This post discusses how to “scrape” the Old School RuneScape Wiki website (referred to as the OSRS Wiki in the remainder of this post). However, the technique discussed in this blog post is not really scraping… rather, it leverages the MediaWiki API to query and parse the OSRS Wiki contents. This is, in my opinion, much more effective than scraping the website content, as the wiki contents are (somewhat!) structured. Say what?! Simply put:
- Using the MediaWiki API: You can get more structured, less messy data
- Using web scraping: You get less structured, more messy data
The remainder of this post is divided into sections that discuss how to extract useful data from the OSRS Wiki with a collection of useful examples of API URLs, which can be tested by copy/pasting into a web browser, or added to a program to automate data extraction.
Contents
- OSRS Wiki Terms of Use
- Background: Wikis, Scraping and MediaWiki API
- MediaWiki API
- Example API URLs for the OSRS Wiki
- Conclusion
OSRS Wiki Terms of Use
As outlined, this post discusses extracting data from the OSRS Wiki. Since we are using their service and data/content, it is important to take two specific things into consideration:
- Adhere to their Copyright. The OSRS Wiki Copyright page includes the following information: Except where otherwise specified, the article revisions on these wikis on and after 1 October 2018 are licensed under Creative Commons BY-NC-SA 3.0. Make sure you read and understand this license.
- Adhere to considerate use of their API. I asked a question about API and terms of use on the OSRS Wiki which they answered and specified some requirements: 1) Adhere to rate limiting, 2) Use a custom user agent; 3) Be reasonable with the number of requests you perform. Although there are no specific guidelines on API usage (at the time of writing this post) - exercise good judgment. Remember, a small group of developers host this content free of charge for the community and we should respect their service and data/content.
Background: Wikis, Scraping and MediaWiki API
It is prudent to first discuss the technology that powers the OSRS Wiki. The OSRS Wiki was previously hosted by Wikia (also known as Fandom) which is a free wiki hosting service. Wikia is exceptionally popular, hosting hundreds of thousands of wikis for a huge variety of topics. Wikia utilizes the open-source MediaWiki software to create and manage the wikis they host. This is a key aspect… and means that the previous Old School RuneScape wiki was hosted on the open source MediaWiki software. However, the OSRS Wiki admins recently announced that they migrated off Wikia and moved to an independently hosted Wiki. However, the new OSRS Wiki is also powered by MediaWiki.
So we know what a Wiki is and how it is powered. But what is an API? And what is scraping? Some readers may be new to these concepts, so it is important to summarize them. Web scraping is a method to extract data from websites - which is usually an automated process. You write a simple program, give it a list of URLs of web pages and program the functionality to extract the data that you are interested in. For example, parsing a web page and extracting an HTML table of item properties. An API, or Application Programming Interface, is quite complex. For the sake of this article, we will use an OSRS Wiki example. You can issue an API query to the OSRS Wiki to give you all the pages that are categorized as Items. Basically, we are saying: “Hey OSRS Wiki, can you please give me every page on your website that is associated with an item?”. Then the OSRS Wiki will respond with a nicely structured list of pages about in-game items.
So… where is the OSRS Wiki API and how can it be used? Well, there are some convergent topics here to understand. Firstly, Wikia provides an API. To be frank, it is not very useful. If you have a look at the Wikia API V1 documentation page you will find very limited features. I initially stopped thinking that I could use an API to query the OSRS Wiki after reading the Wikia API documentation because the functionality of the Wikia API was too limited. However, that was until I realized that Wikia uses MediaWiki. And MediaWiki has an excellent API, and excellent API documentation. Since the OSRS Wiki left Wikia, this doesn’t matter anymore… Nevertheless, the new OSRS Wiki also uses MediaWiki. This Wiki stuff may seem obvious for many people, but I had never really been exposed to wikis and had never installed or managed one. Anyway, after a quick look at the MediaWiki API documentation and tutorials, I suddenly realized the power of the API.
MediaWiki API
The MediaWiki Wiki provides exception documentation on their API. However, it still took me a little while to start getting used to writing useful API queries, especially since there were no examples specifically for the OSRS Wiki. It was even worse because the old OSRS Wikia site had a strange (maybe old) version of the API. The new OSRS Wiki seems to run a newer version and the examples in the API documentation will mostly work without modification. Anyway, I thought it would be useful to share the knowledge I gained. Here is a quick overview of how to use the MediaWiki API specifically for the OSRS Wiki…
The OSRS Wiki has a base URL of:
https://oldschool.runescape.wiki/When you enter this URL, you will be directed to the OSRS Wiki home page (landing page). To access the MediaWiki API, you need to append api.php to the end of the base URL, as demonstrated below:
https://oldschool.runescape.wiki/api.phpEntering this URL will load a page on the OSRS Wiki and provide you with some documentation about the MediaWiki API, including some of the features available. It is a pretty large documentation page and has a lot of information. But I find the official MediaWiki Wiki documentation on the API to be much easier to navigate - and it has excellent interactive examples.
Using the MediaWiki API
To use the MediaWiki API you need to build a URL that includes the base API URL with additional actions and parameters. I like to think of the process like asking the OSRS Wiki questions. Below is an example of a query action. As the name implies, this action queries (or asks) the API questions and is returned results. In the example below, the query asks the OSRS Wiki for the specific page which matches the title of Abyssal whip.
https://oldschool.runescape.wiki/api.php?action=query&prop=revisions&rvprop=content&titles=Abyssal_whipWe should break down this example a little to understand what is happening:
https://oldschool.runescape.wiki/api.php?: The base API URL, anything after the question mark will contain the action and other parametersaction=query: The action to perform, in this case, a query- Any remaining parameters should be appended after the action using an ampersand character (
&) prop=revisions: Get the most recent revision (the latest edit)rvprop=content: Get the actual content of the pagetitles=Abyssal_whip: The title of the page to query
The query above fetches the contents of the OSRS Wiki page for the Abyssal whip. I would recommend opening the API query and the actual web page for the Abyssal whip and comparing the contents. You should be able to determine that the content of the two pages are the same but in a different format. The difference:
- The API query returns the structured data for the MediaWiki software to build the actual web page
- The wiki uses the structured data to build a beautiful and visually pleasing web page for the delivery of content to end users
We should look at another, more powerful example. In this example, we will use another action, this time the opensearch action. This action allows us to search the entire OSRS Wiki for keywords on page titles (not actual page content). In the example below, the action searches for any page on the OSRS Wiki that contains the title abyssal.
https://oldschool.runescape.wiki/api.php?action=opensearch&search=abyssal&format=json&limit=20If you open this API URL in another browser window you should see the following result:
[
"Abyssal",
[
"Abyssal",
"Abyssal whip",
"Abyssal Sire",
"Abyssal demon",
"Abyssal Sire/Strategies",
"Abyssal dagger",
"Abyssal tentacle",
"Abyssal bludgeon",
"Abyssal guardian",
"Abyssal walker",
"Abyssal book",
"Abyssal leech",
"Abyssal orphan",
"Abyssal portal",
"Abyssal demon head (mounted)",
"Abyssal head",
"Abyssal bracelet",
"Abyssal Nexus",
"Abyssal Area",
"Abyssal demon head (stuffed)"
],
[
"https://oldschool.runescape.wiki/w/Abyssal",
"https://oldschool.runescape.wiki/w/Abyssal_whip",
"https://oldschool.runescape.wiki/w/Abyssal_Sire",
"https://oldschool.runescape.wiki/w/Abyssal_demon",
"https://oldschool.runescape.wiki/w/Abyssal_Sire/Strategies",
"https://oldschool.runescape.wiki/w/Abyssal_dagger",
"https://oldschool.runescape.wiki/w/Abyssal_tentacle",
"https://oldschool.runescape.wiki/w/Abyssal_bludgeon",
"https://oldschool.runescape.wiki/w/Abyssal_guardian",
"https://oldschool.runescape.wiki/w/Abyssal_walker",
"https://oldschool.runescape.wiki/w/Abyssal_book",
"https://oldschool.runescape.wiki/w/Abyssal_leech",
"https://oldschool.runescape.wiki/w/Abyssal_orphan",
"https://oldschool.runescape.wiki/w/Abyssal_portal",
"https://oldschool.runescape.wiki/w/Abyssal_demon_head_(mounted)",
"https://oldschool.runescape.wiki/w/Abyssal_head",
"https://oldschool.runescape.wiki/w/Abyssal_bracelet",
"https://oldschool.runescape.wiki/w/Abyssal_Nexus",
"https://oldschool.runescape.wiki/w/Abyssal_Area",
"https://oldschool.runescape.wiki/w/Abyssal_demon_head_(stuffed)"
]
]We should break down this example a little to understand what is happening:
https://oldschool.runescape.wiki/api.php?: The base API URL, anything after the question mark will contain the action and other parametersaction=opensearch: The action to perform, in this case, an opensearch- Any remaining parameters should be appended after the action using an ampersand character (
&) search=abyssal: The search term usedformat=json: Return the results in JSON format (not the default XML format)limit=20: Return up to 20 search results (the default is 10, and the OSRS Wiki seems to limit this to 20 maximum)
As you can see by the output of the search, the API search found a collection of pages on the OSRS Wiki that contain the keyword abyssal. We could write a simple program to iterate (loop) through each of the results and grab the page contents (using the first query we looked at). To use the result, we could visit the actual web page using the following logic (in pseudo code):
"https://oldschool.runescape.wiki/w/" + page_titleTo use the API to fetch the contents of each of the pages found we could use the following API URL:
"https://oldschool.runescape.wiki/api.php?action=query&prop=revisions&rvprop=content&titles=" + page_titleFor example:
https://oldschool.runescape.wiki/api.php?action=query&prop=revisions&rvprop=content&titles=Abyssal_tentacleNote: In the above example, we should replace the spaces in the returned search result with the underscore character (_) to correctly query the page title, but you are not forced to perform this change and from my experience, the API will still load correctly without this change.
MediaWiki API: Data Formats
According to the MediaWiki API documentation, there used to be support for a variety of different output formats. The documentation states that this complicated development and the current roadmap of development is to standardize to only support JSON. However, they do still support XML and PHP generic outputs. From my investigation, it seems that by default the new OSRS Wiki returns JSON formatted data. In the old OSRS Wiki, if you wanted JSON formatted data, you had to append a &format=json to the end of the query, for example:
https://oldschool.runescape.wiki/api.php?action=query&prop=revisions&rvprop=content&titles=Abyssal_tentacle&format=jsonIt is really up to you what data format you wish to use, but I would recommend using JSON as it is widely supported by many programming languages and very easy to parse. It is also very easily read by humans compared to some of the other data formats.
Example API URLs for the OSRS Wiki
This section documents some interesting API URLs for executing against the OSRS Wiki. For each example, a brief description has been provided, as well as the actual URL required. I would recommend reading the description and trying the example URL in a web browser to get an idea of the results returned.
Get Page Contents
You may find it useful to query a specific page and get the actual page content about any page in the OSRS Wiki. The following URL provides an example of how to get the actual page content for the Abyssal tentacle including:
https://oldschool.runescape.wiki/api.php?action=query&prop=revisions&rvprop=content&titles=Abyssal_tentacle&format=jsonaction=query: The action to perform, in this case, a queryprop=revisions: Get the most recent revision (the latest edit)rvprop=content: Get the actual content of the pagetitles=Abyssal_tentacle: The title of the page to query
Get Page Templates
The OSRS Wiki utilizes a variety of templates to produce structured data. For example, the OSRS Wiki using Infoboxes to display data about items or npcs. Take the example image below which displays two different Infoboxes for the Abyssal whip item.
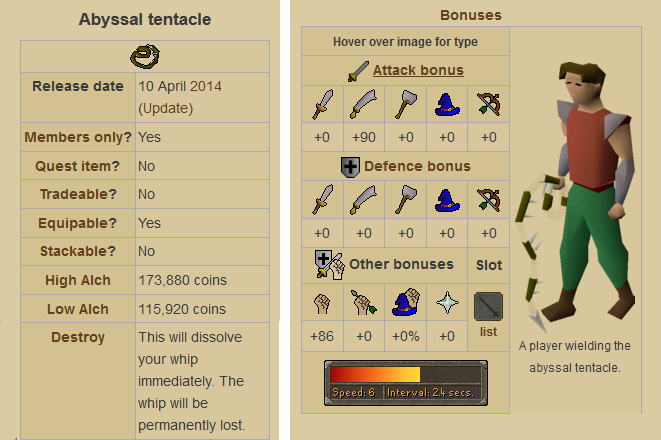
The Infobox on the left is an Infobox Item template that displays information about an item including high alchemy, low alchemy, release date, and members item status. While the Infobox on the right is an Infobox Bonuses template that displays the stats, or item bonuses, that a specific item has. The Infoboxes vary throughout the OSRS Wiki, but these two examples are commonly seen for items.
To extract a list of templates used on a specific page, you can query a page by the title and then specify that you want the templates used.
https://oldschool.runescape.wiki/api.php?action=query&prop=revisions&rvprop=content&titles=3rd_age_pickaxe&prop=templatesaction=query: The action to perform, in this case, a queryprop=revisions: Get the most recent revision (the latest edit)rvprop=content: Get the actual content of the pagetitles=3rd_age_pickaxe: The title of the page to queryprop=templates: Specify you want to fetch a list of the templates used on the page
If you do not want to programmically determine the template, you can easily get the template name using the Edit function on the OSRS Wiki. If you select the Edit button on any page, then click on the area that you think is a template, a box will highlight the template and display the name. See the image below for an example:

Extract All Categories
Wikis are usually organized into categories and each page is tagged with specific categories. This allows a specific page, or topic, to be associated with a variety of different categories. The following URL lists the first 500 categories available on the OSRS Wiki:
https://oldschool.runescape.wiki/api.php?action=query&aclimit=500&list=allcategories&format=jsonfm&formatversion=2action=query: The action to perform, in this case, a queryaclimit=500: Get the first 500 categorieslist=allcategories: Get the actual list of categoriesformat=json: Ask for the returned data to be in JSON format
Conclusion
Well done if you made it this far! This post just scraped the surface (pun intended) of using the OSRS Wiki API. Hopefully, you got some useful information from it but just remember, please adhere to the OSRS Wiki terms of use. They provide an excellent ad free resource and we should not overuse their service. In the next post, I will include some more information on using Python programs to extract data from the OSRS Wiki. You can also check out some Python tools I have written to extract data from the OSRS Wiki for my OSRS Item Database project (osrsbox-db). They are available on my OSRSBox GitHub database repository. Until next time… happy scaping everyone!